批量订阅了一些博客
接上回。昨天拿到了 900 多个个人博客的链接并进行了一番简单分析。现在有了新的需求,我想订阅这些网站,但是一个个点进去看实在太辛苦了,我想的是如果能一键全部订阅了,到时候看到不合适的再取消订阅总比一个个订阅要来的方便吧。
首先,要知道一个博客有没有可用的 RSS 订阅源,在 html 中寻找 type = application/rss+xml 的 link 标签即可,xpath 语法为
1 | rss = html.xpath('//link[contains(@type, "application/rss+xml")]/@href') |
拿到 RSS 源的地址后,我一开始以为 FreshRSS 提供了添加新订阅的 API,然而并没有。好在 FreshRSS 是自建的服务,数据库就掌握在自己手里,不行就直接 SQL 语句插入到表里吧,看了一下 FreshRSS 的订阅表结构
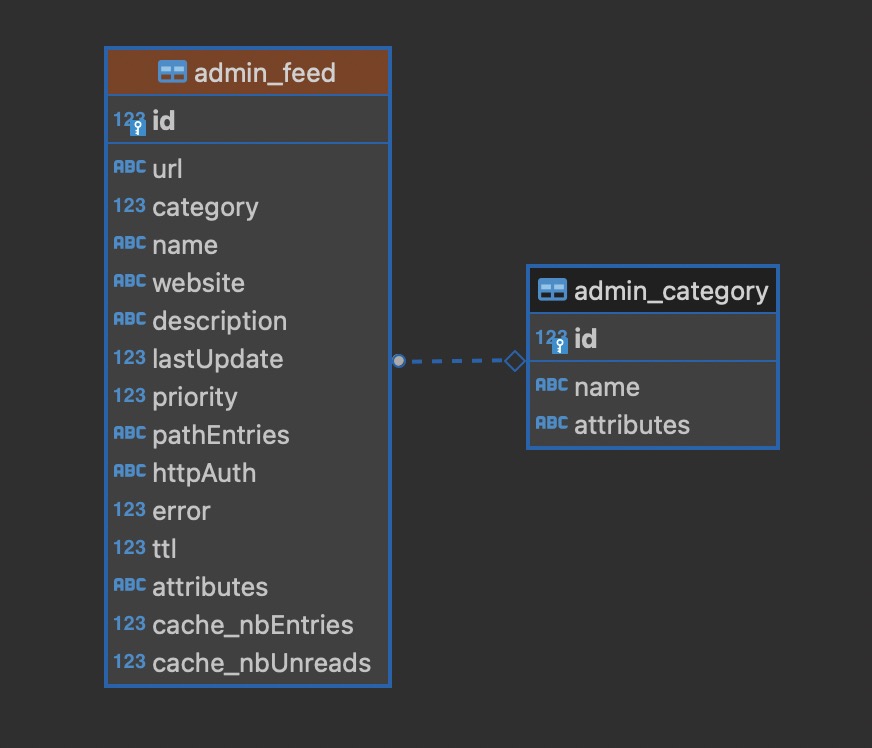
关键字段为, 其余字段和其它行一样即可
| 字段 | 含义 |
|---|---|
| url | RSS 源地址 |
| category | 分类,参照 admin_category 表 |
| name | 站点名称 |
| description | 站点描述 |
那么只要在 python 程序中获取到这些字段的值然后组装成 SQL 语句,再复制去数据库客户端执行即可。(这里也可以 python 直接连接 postgres 数据库去执行脚本,但没什么必要)
url 已经获取到了,category 是固定值,在我的数据库里就是 博客 对应的 category 值 3,那么拿到 name 和 description 即可。其实重点是 name,每次新文章发布时都会显示在列表上,description 可有可无。
获取网站标题的 xpath 语句为
1 | title = html.xpath('//title')[0].text |
这里获取到的就是我们用浏览器打开网页时标签页的名称啦,这个名称常常是 xxx - yyy 或者 xxx | yyy 的格式,分别提取出来 xxx 是站点名称,yyy 是站点描述。这是一般的情况,有些网站只有 xxx,那么站点名称和描述就直接取这个就好了。完整代码
1 | def fetch(url): |
输出结果如下
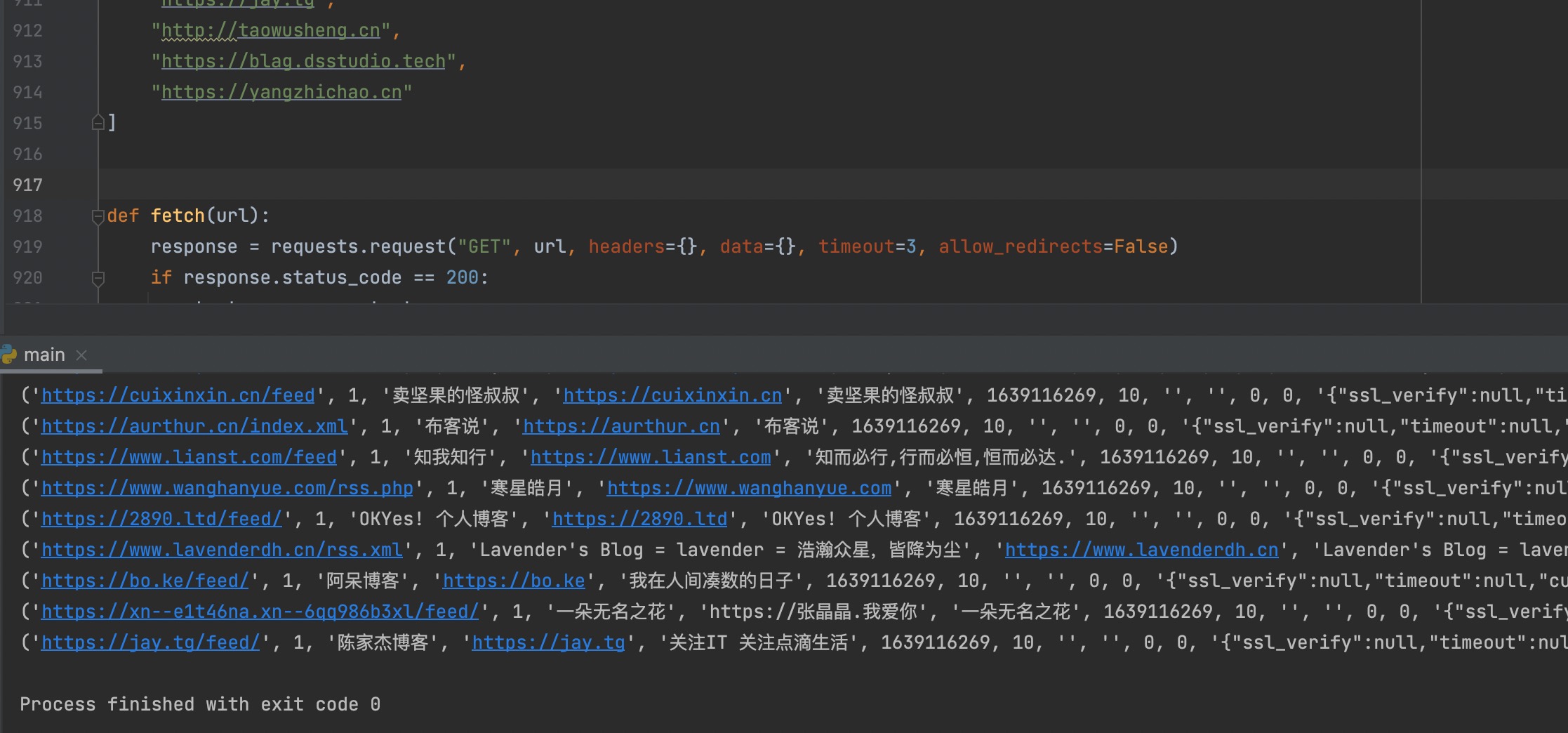
粘贴到数据库客户端执行之,每一行前面加上
1 | INSERT INTO public.admin_feed |
末尾加上 (由于部分博客我们已经订阅过了,再次插入会引起唯一约束冲突)
1 | ON CONFLICT ("url") DO UPDATE SET "lastUpdate" = 1639116269; |
另外 SQL 语句中的单引号需要手动处理下。处理后的每一行的一个例子如下
1 | insert INTO public.admin_feed (url, category, name, website, description, "lastUpdate", priority, "pathEntries", "httpAuth", error, ttl, "attributes", "cache_nbEntries", "cache_nbUnreads") VALUES ('https://jay.tg/feed/', 1, '陈家杰博客', 'https://jay.tg', '关注IT 关注点滴生活', 1639116269, 10, '', '', 0, 0, '{"ssl_verify":null,"timeout":null,"curl_params":null}', 10, 0) ON CONFLICT ("url") DO UPDATE SET "lastUpdate" = 1639116269; |
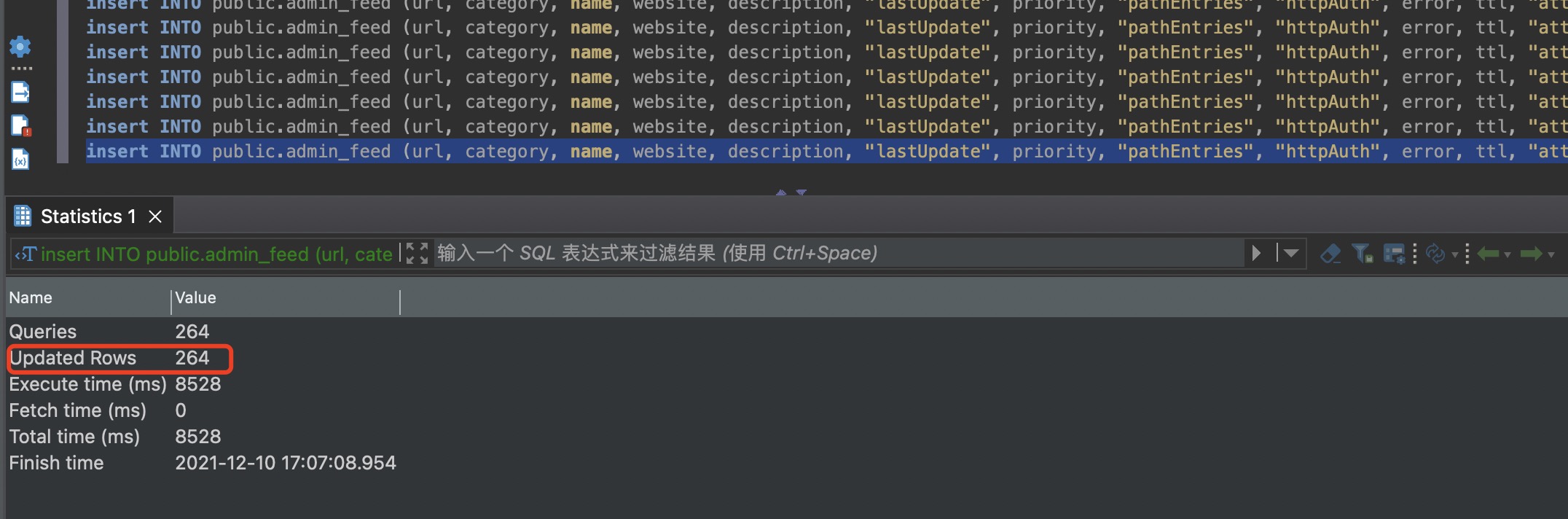
SQL 执行完成。可以看到,一共添加了 264 个订阅。在 FreshRSS 界面点一下刷新
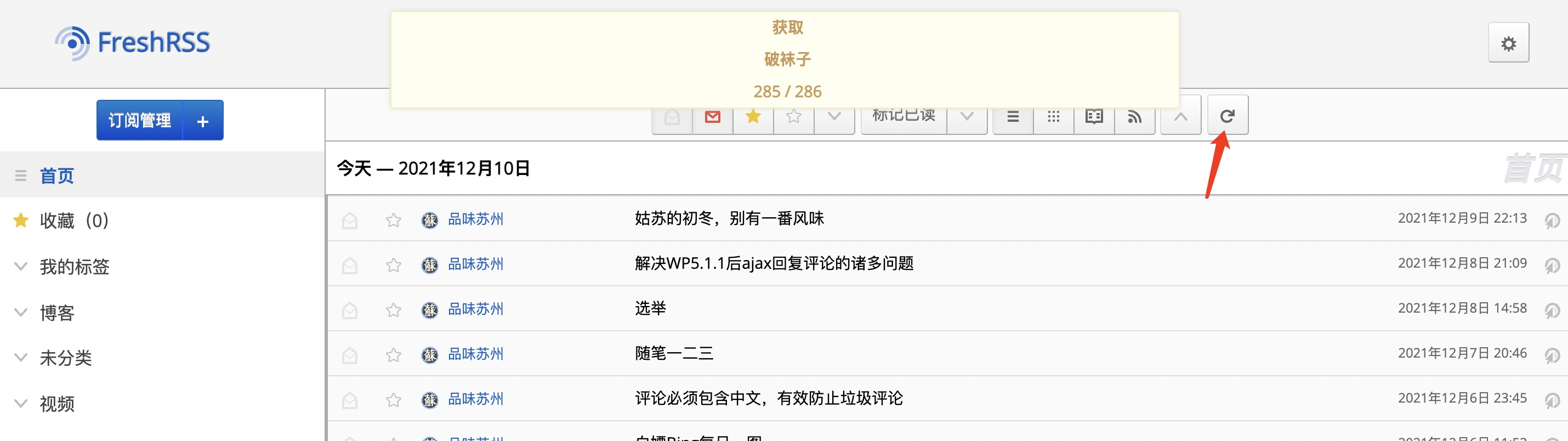
一下子刷新出 3000 多条文章,有点考验 FreshRSS 性能。但出了点小意外,怎么都跑到未分类了。。。
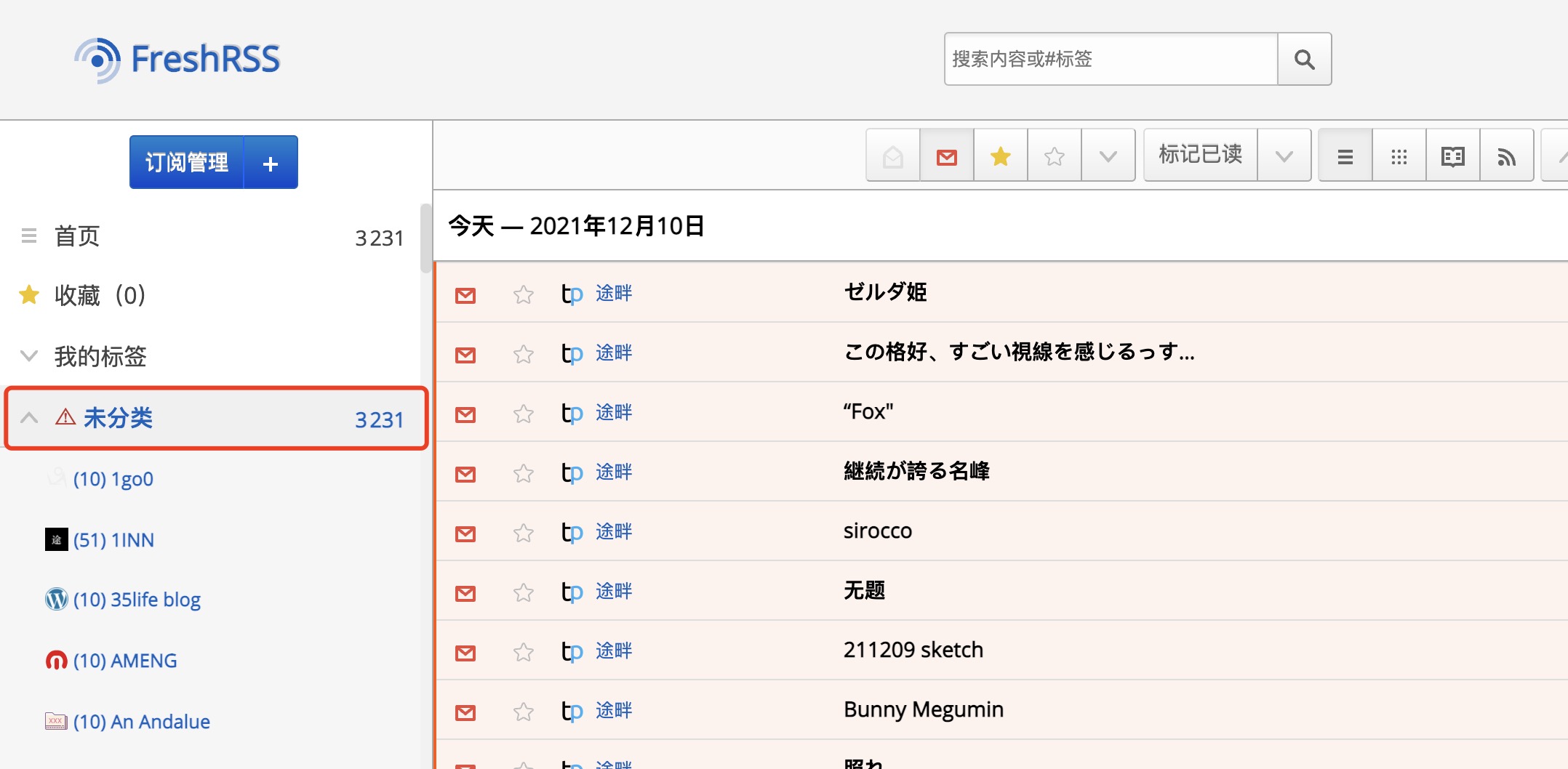
忘记更改 category 的值了,更新一下。
1 | update public.admin_feed set category = 3 where category = 1; |
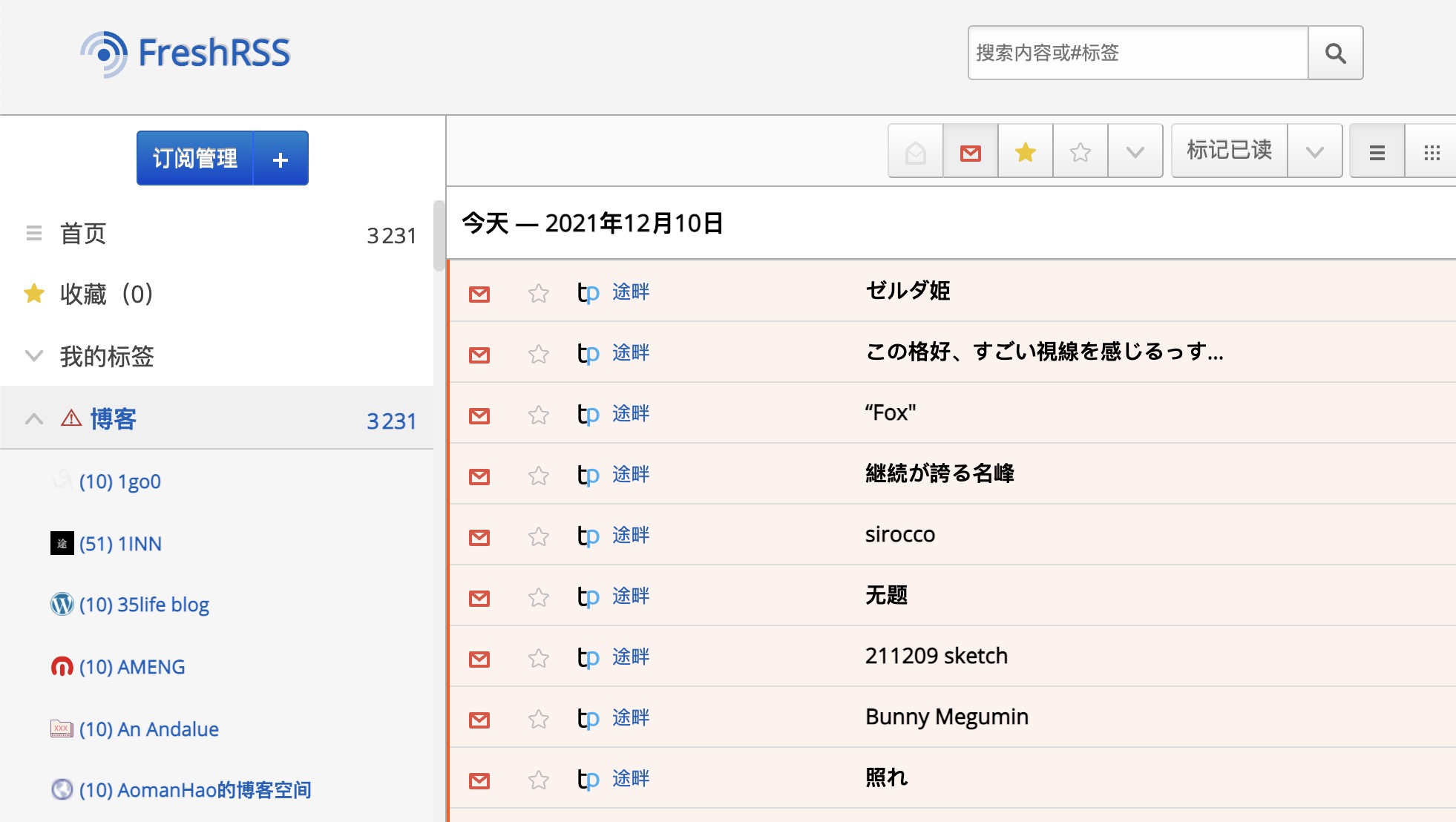
好了,后面再看情况去删除部分我们不希望订阅的就行了,比如一直发布我们不感兴趣或者毫无价值的内容的博客,当然,这部分肯定是少数了。

