首先是决定更换域名,由 lixinyu.info 改为 omgxy.com 。一直使用 info 这个域名,原因无非是只有这个域名备案了,可以解析到腾讯云国内服务器,速度足够快。这次一来换成了主流的 com 域名,其次缩短了两个字母,我认为这个新域名还是挺好记的。老域名绑定了大概十几个站点,好在都是通过 Nginx 反代的,经过数小时的努力,所有站点都平滑过渡到了新域名。新域名还没备案,临时找了一个还有两个月到期的香港 VPS 挂了一个 frps 做了下中转,等新域名备案了再改下解析即可。
回到正题,博客这个东西我是一直有在弄的,但是写的一共也没几篇。常常是来了兴致就捯饬捯饬,玩不一会就丢到一边,放任其荒芜。近来关注到一些的博客站点,或十年如一日,沉淀着岁月的美好;或形式别具一格,观之赏心悦目。。。感触颇深。
最近发现一个叫 “十年之约” 的项目,大概是一个博客聚合站点,抱团取暖的感觉。浏览了一下上面陈列的一些站点,也确实有一些质量比较高的,展示了从 2017 年至今每年加入的博客站点,粗略估计收录有千余个博客站点。但是浏览起来感觉有些费劲,里面也不全是精品,有些甚至都打不开了。于是有了写个小爬虫程序的想法。中午的休息时候就在那写。

首先看这个展示页面,没有发现接口调用,像是静态页面或服务端渲染的,接口调用是行不通了。那就用 python 请求 html 取解析吧。然而这个页面只显示网站的 logo 和名称,没有关键的链接,链接需要点击进每一个站点才能获取到。好在详情页是一个可以遍历的 url,比如 https://www.foreverblog.cn/blog/2008.html 这个 2008 应该就是自动编号了,只要找到最新加入的博客编号 id 然后从 0 开始遍历到这个数就好了。还挺简单的。代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import requests
from lxml import etree
import time
def fetch(index):
url = "https://www.foreverblog.cn/blog/" + str(index) + ".html"
payload = {}
headers = {
'authority': 'www.foreverblog.cn',
'pragma': 'no-cache',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7,pt;q=0.6',
'cookie': '*********',
'sec-gpc': '1'
}
response = requests.request("GET", url, headers=headers, data=payload)
if response.status_code == 200:
text = response.text
html = etree.HTML(text)
href = html.xpath('//a/@href')
if len(href) > 12:
print(href[12])
else:
print("------------")
if __name__ == '__main__':
for i in range(500, 2560):
fetch(i)
time.sleep(0.5)
|
抓取到的数据如下
1
2
3
4
5
6
7
| https://too.pub
https://gorpeln.com
http://www.liusu.me
https://muuzi.cn
https://juantu.cn
https://couqiao.net/
... ...
|
统计了一下共有 908 条。随便选择几个访问了下,依然不乏一些年久失修的或者无法访问的站点。
面对这些数据,我自然就想到一个问题,这 900 个网站,有多大的比例是无法访问的?大家偏爱的域名和建站程序是什么?
首先是能否访问,逐个去访问看下返回的状态码是不是 200 即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def fetch(url, s, f):
response = requests.request("GET", url, headers={}, data={}, timeout=3)
if response.status_code == 200:
s += 1
else:
print(url)
f += 1
return s, f
if __name__ == '__main__':
succeed, failed = 0, 0
for site in sites:
try:
succeed, failed = fetch(site, succeed, failed)
time.sleep(0.1)
print(str(succeed) + " | " + str(failed))
except (requests.exceptions.ConnectionError, requests.exceptions.ReadTimeout) as e:
failed += 1
print(site)
print("-------------------")
print(str(succeed) + " | " + str(failed))
|
最终统计结果为 908 个站点中有 156 个无法正常访问,约占 17.18%
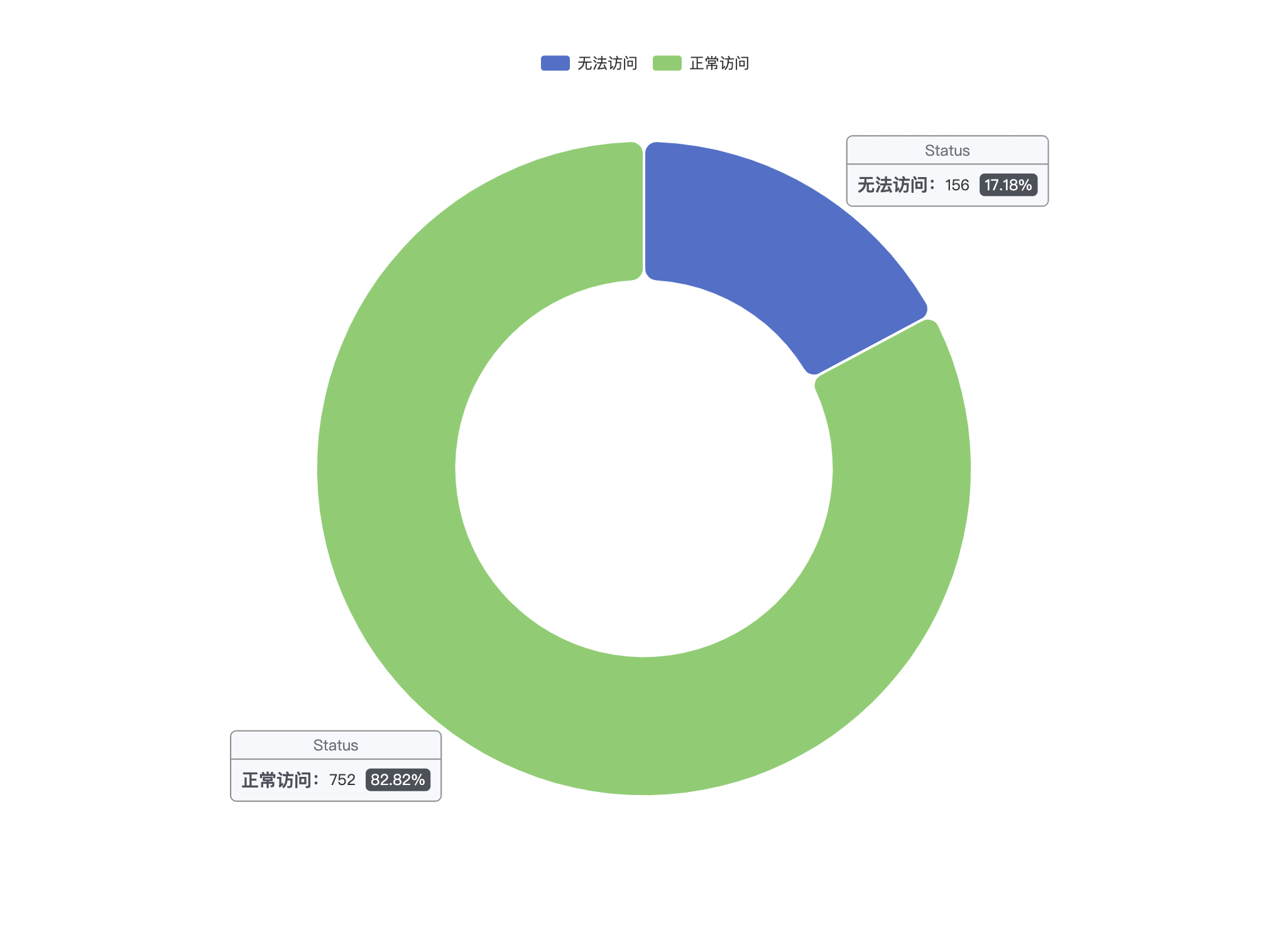
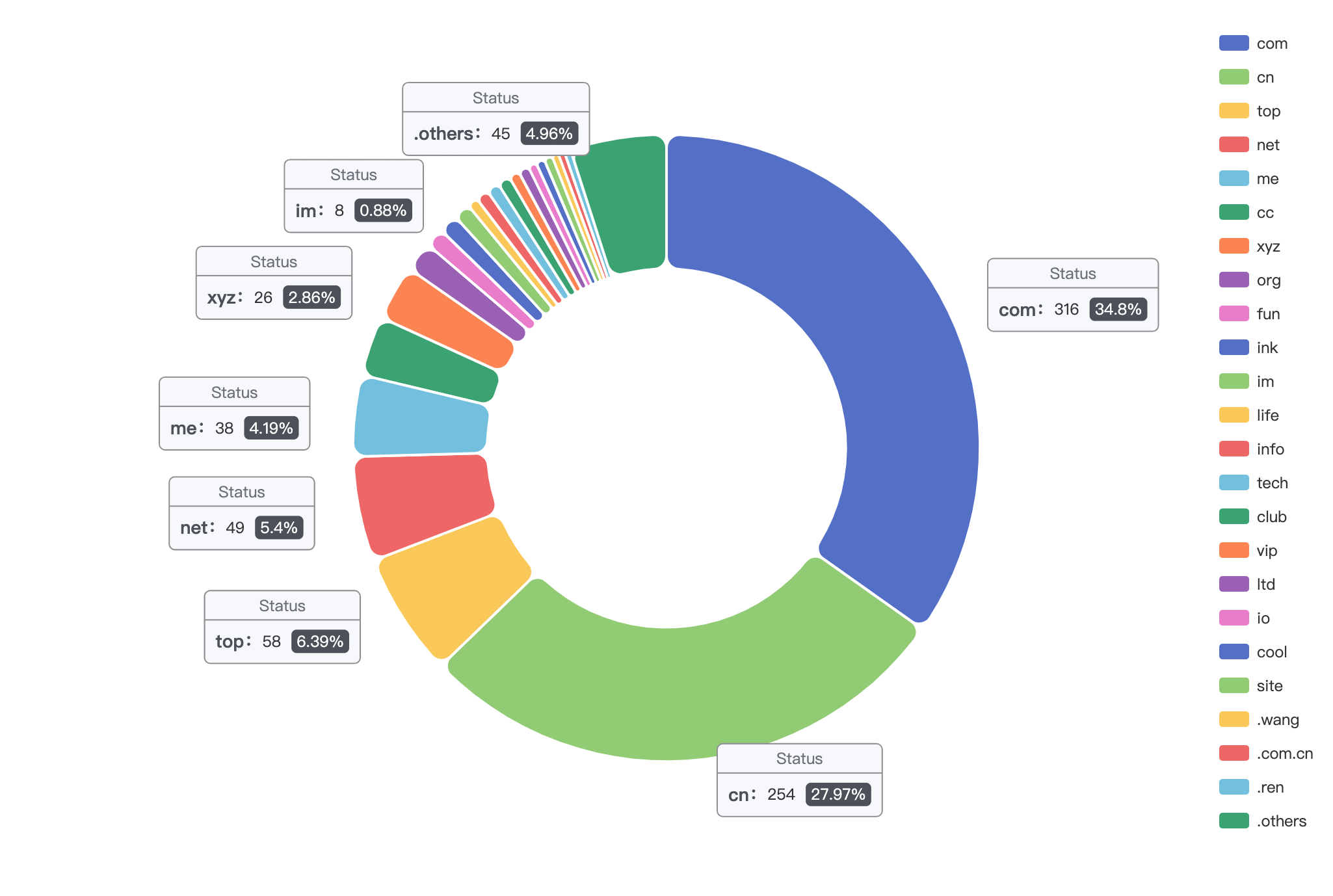
域名方面是, com 和 cn 占据超过 60%
至于建站程序就稍微有点棘手了,目前也只能看看我所知道的一些建站工具在这些网站中的使用比例。看一个站点用的是什么程序,校验特征即可。
首先是 Wordpress,一般来说默认的登录页 /wp-login.php 是可以访问的,但还有更简单的判断方法。
Wordpress、Hexo 和 Hugo 站点的话一般在 html 中会有一个名叫 generator 的 meta 标签标识 Hexo 的版本号,如
1
| <meta name="generator" content="WordPress 5.3.10">
|
1
| <meta name="generator" content="Hexo 5.4.0">
|
1
| <meta name="generator" content="Hugo 0.89.4">
|
Typecho 站点特征不明显,一般在页脚放置官网链接 https://typecho.org,以此为特征。编码实现如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| def fetch(url, wp, hx, hg, tc):
response = requests.request("GET", url, headers={}, data={}, timeout=3)
if response.status_code == 200:
text = response.text
if "https://typecho.org" in text:
tc += 1
return wp, hx, hg, tc
html = etree.HTML(text)
if html is None:
return wp, hx, hg, tc
generator = html.xpath('//meta[contains(@name, "generator")]/@content')
if len(generator) == 0:
return wp, hx, hg, tc
if generator[0].startswith("WordPress"):
wp += 1
return wp, hx, hg, tc
if generator[0].startswith("Hexo"):
hx += 1
return wp, hx, hg, tc
if generator[0].startswith("Hugo"):
hg += 1
return wp, hx, hg, tc
return wp, hx, hg, tc
if __name__ == '__main__':
wordpress, hexo, hugo, typecho = 0, 0, 0, 0
for site in sites:
try:
wordpress, hexo, hugo, typecho = fetch(site, wordpress, hexo, hugo, typecho)
time.sleep(0.1)
print(wordpress, hexo, hugo, typecho)
except (requests.exceptions.ConnectionError, requests.exceptions.ReadTimeout) as e:
print(site)
print("-------------------")
print(wordpress, hexo, hugo, typecho)
|
(平时也不怎么写 Python,有点乱,以实现功能为主)
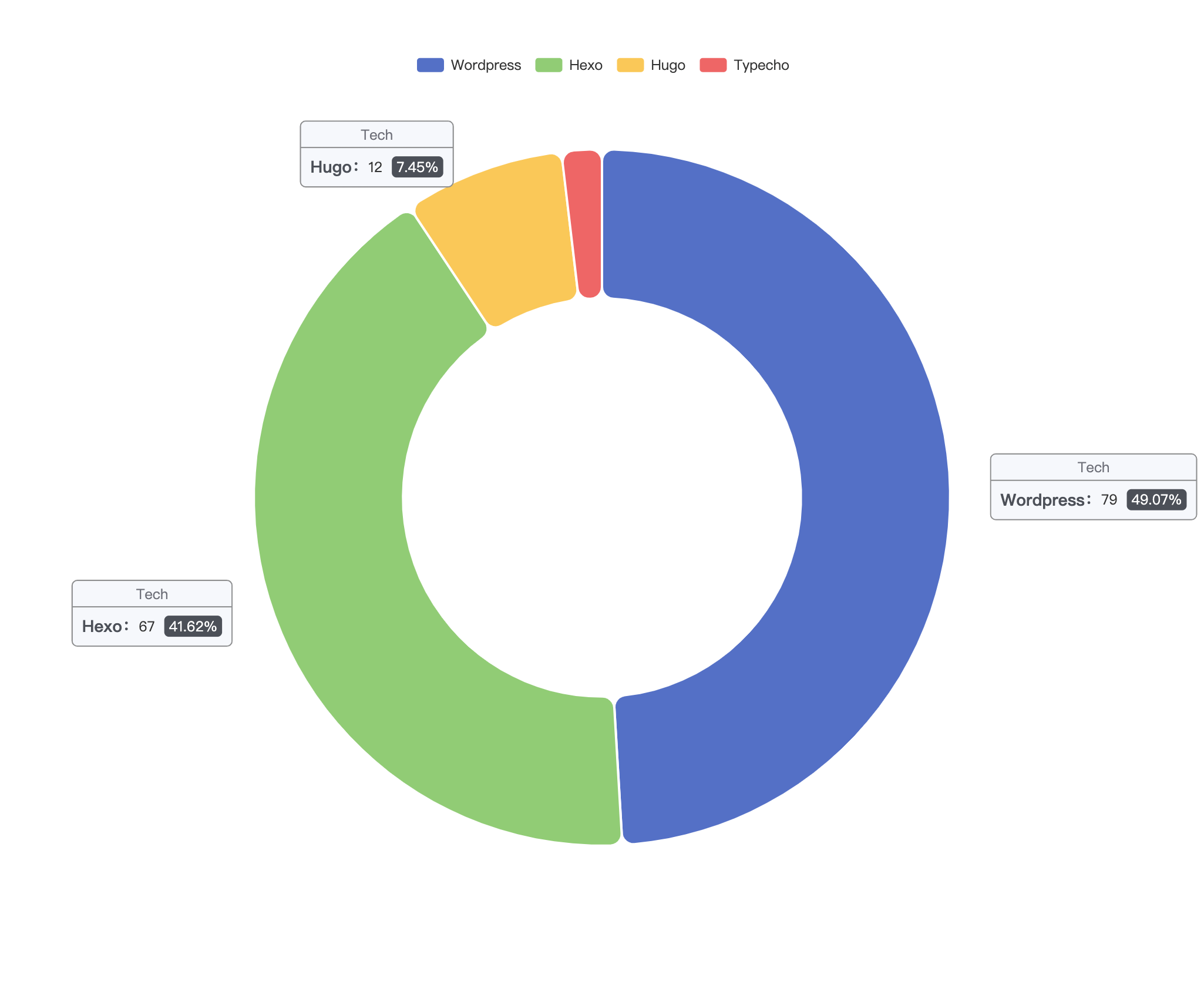
调查到此结束,建站程序统计误差应该会比较大,样本也比较小,参考价值不大,但从中可以看出,Wordpress 和 Hexo 的份额毫无疑问还是最大的,Hexo 的占比有点超出预期。另外 Typecho 感觉应该不止这么一点,猜测可能是有些人把底部的链接去掉了导致统计结果出现了偏差。

